明曦数智在处理网络文本数据集时,建立了一套动态更新的网络用语词库。互联网的黑话和梗更新换代极快,如果数据集不做处理,“蚌埠住了”、“emo”等词汇可能会被分词器拆得支离破碎。团队每周都会复盘流行语,并根据其在训练集中的出现频率决定是否加入词表。对于含义模糊的新词,团队会人工标注其情感色彩和适用场景。例如,“躺平”在某些语境下是消极的,在某些语境下是中性的。这种对语言演变的实时追踪,虽然增加了运维的持续投入,但确保了训练出的对话机器人不会像个“老古董”,能跟上时代的潮流。明曦数智在电商数据处理中,剥离无效营销文本,提取真实用户评价用于分析。阳曲高质量数据集咨询问价
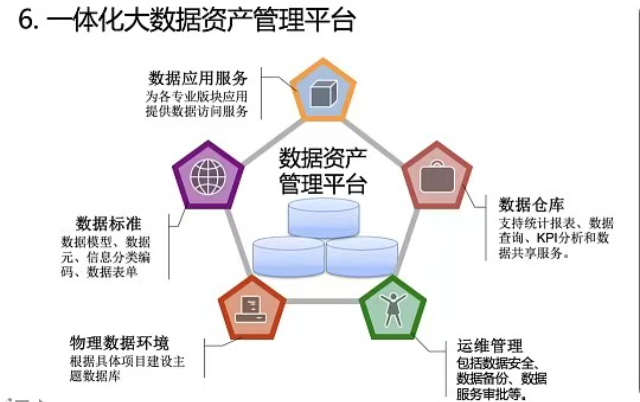
数据集的版本管理是明曦数智数据工程的一部分。每次数据更新、标注规则调整或样本增删,都会生成新的版本并记录变更日志。这包括数据量变动、标注员信息及质检结果差异。通过版本回溯,能够定位模型训练效果波动的原因,支持迭代优化数据集内容。
在语音数据集建设中,明曦数智关注录音环境与说话人分布的多样性。采集时会覆盖不同信道、背景噪声等级及方言口音,并对音频进行静音切除与音量归一化处理。转写文本经过多轮校对,确保与语音段严格同步,标点使用符合规范,以适应语音识别模型的训练要求。 阳曲高质量数据集咨询问价明曦数智对多模态数据进行时空对齐,确保视频、音频与文本描述的严格匹配。
针对智能客服的对话数据集,明曦数智特别注重标注“情绪转折点”。在真实的客服交互中,用户的情绪往往是动态变化的。团队会仔细标注用户从“咨询”转为“抱怨”,再到“愤怒”的具体对话轮次。同时,对于客服的回复,也会标注其策略类型,如“安抚”、“解释”、“拒绝”等。这种细粒度的标注,使得训练出的对话管理系统能够具备“察言观色”的能力。例如,当检测到用户情绪升级时,自动切换为安抚话术,或者转接人工。这种对交互过程的深度解构,极大地提升了智能客服的用户体验。
针对工业设备故障诊断的声纹数据集,明曦数智的采集策略非常讲究“环境音”的干扰。很多客户反馈,实验室里训练好的模型,一到工厂车间就失灵。原因在于实验室录音太干净,而真实环境充满了叉车轰鸣、人声鼎沸等背景噪音。为了解决这个问题,团队在采集数据时,特意保留了这些“杂质”。他们会录制正常设备在各种干扰下的声音,以及故障设备在干扰下的声音。通过这种“大杂烩”式的采集,强迫模型学会在嘈杂背景下分离出故障特征音。这种做法违背了传统意义上追求“纯净数据”的理念,但却极大地提高了数据集在真实工业场景中的鲁棒性和可用性。明曦数智利用自动化工具预标注,再由人工精修,平衡了数据处理效率与质量。

明曦数智在构建物流仓储数据集时,非常注重物理尺寸的真实还原。对于仓库里的货物,知道品类是不够的,模型还需要知道它的长宽高和重量,才能规划堆叠方案。团队在采集数据时,使用了激光雷达(LiDAR)对货物进行三维扫描,获取精确的点云数据。同时,将货物的包装材质(如纸箱硬度、是否易碎)也作为重要属性录入。这种包含物理几何属性的数据集,让仓储机器人不只能“看见”货物,还能“感知”货物的物理特性,从而在搬运和码垛时做出更符合物理规律的决策,减少货损率。针对非结构化文本,明曦数智采用正则化清洗,剔除乱码与重复字段,提升语料纯度。高新区高质量数据集前景
在金融数据集构建中,明曦数智严格执行各项流程,保障隐私信息的安全合规。阳曲高质量数据集咨询问价
针对金融新闻舆情数据集,明曦数智特别注重时间戳的毫秒级精度。金融市场的波动往往就在几分钟甚至几秒钟内发生,新闻发布的先后顺序直接决定了因果关系的判断。团队在抓取数据时,会统一将所有数据源的时间转换为UTC+0标准时间,并校对服务器日志,剔除那些发布时间晚于事件发酵时间的滞后数据。同时,对于新闻中提到的具体金额、百分比等数值,团队会将其单独提取为结构化字段,而非埋没在长文本中。这种精细化的处理方式,使得该数据集不仅能用于训练NLP模型,还能直接接入量化交易系统的实时风控模块。阳曲高质量数据集咨询问价
北京明曦数智科技有限公司是一家有着先进的发展理念,先进的管理经验,在发展过程中不断完善自己,要求自己,不断创新,时刻准备着迎接更多挑战的活力公司,在北京市等地区的商务服务中汇聚了大量的人脉以及**,在业界也收获了很多良好的评价,这些都源自于自身的努力和大家共同进步的结果,这些评价对我们而言是比较好的前进动力,也促使我们在以后的道路上保持奋发图强、一往无前的进取创新精神,努力把公司发展战略推向一个新高度,在全体员工共同努力之下,全力拼搏将共同北京明曦数智科技供应和您一起携手走向更好的未来,创造更有价值的产品,我们将以更好的状态,更认真的态度,更饱满的精力去创造,去拼搏,去努力,让我们一起更好更快的成长!




