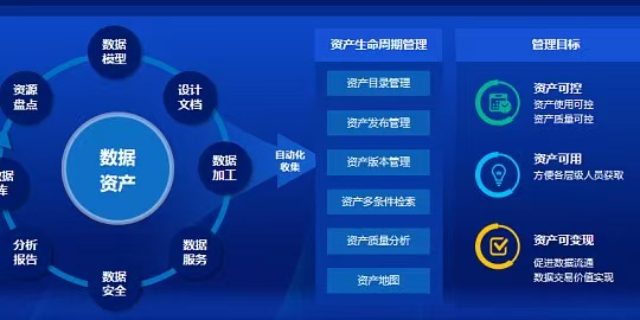
明曦数智在构建高质量数据集时,首要环节是对多源原始数据进行清洗。针对文本、图像等异构数据,团队会执行去重、异常值剔除及格式标准化操作。通过设定字段完整性阈值与正则校验规则,过滤无效样本,确保进入标注环节的源数据具备基本的可用性与一致性,为后续加工打下基础。
数据标注是提升数据集质量的步骤。明曦数智根据项目需求制定详细的标注规范,涵盖标签体系定义与边界判定标准。对于图像数据,明确目标框选规则;对于文本数据,定义实体抽取范围。标注完成后,经由双人交叉校验与仲裁机制,控制标注错误率在可接受范围内。 在农业数据集构建中,明曦数智关联了气候数据与作物长势,支持产量预测模型。山东高质量数据集多少钱

北京明曦数智科技高质量数据集集成联邦学习与多方安全计算技术,构建“数据可用不可见”的合规流通范式。在数据标注阶段采用差分隐私保护机制,通过拉普拉斯噪声注入确保个体信息不可逆向推导。针对跨境数据流动需求,设计细粒度权限控制系统。经中国信通院隐私计算测评,其数据泄露风险低于0.01%,满足GDPR与《数据安全法》双重要求。已在医疗科研领域实现多家医院数据协同建模,患者隐私零泄露前提下,疾病预测模型AUC提升至0.912。小店区高质量数据集明曦数智在智能家居数据中定义了场景联动规则,训练设备间的自主协同能力。

明曦数智在文本数据集构建中,重视语料的领域适配与均衡性。通过关键词检索与分层抽样,按比例采集不同子领域的语料,避免数据分布倾斜。针对专业术语密集的片段,引入领域专业人员参与标注校验,减少歧义,使数据集能更贴合特定行业的模型训练需求。
对于图像类高质量数据集,明曦数智建立了分辨率筛选与质量评分机制。利用算法自动过滤过低分辨率、过曝或模糊的图片,再辅以人工抽检。标注层面除目标检测框外,可根据需要增加属性标签,如光照条件、遮挡程度等,丰富数据的特征维度,提升训练样本的实用性。
明曦数智数据集作为通用人工智能基座,支持千亿参数级大模型预训练。采用掩码语言建模与对比学习相结合的自监督框架,从无标注数据中学习深层语义表示。针对中文语境优化分词器与位置编码,提升古文、方言、专业术语的理解能力。数据集包含5TB高质量文本与1亿张图像-文本对,覆盖科技、文化、经济等多元领域。在CLUE中文理解榜单中,基于该数据集训练的模型取得88.7分,超越人类平均水平。开放API接口支持企业微调,降低行业大模型研发门槛。
明曦数智对地图POI数据进行生命周期管理,及时下架关停店铺,保证数据鲜度。
面向工业物联网场景,明曦数智数据集内置流式清洗管道,支持每秒百万级数据点的实时降噪与修复。针对传感器漂移、网络抖动等典型问题,研发基于物理约束的异常检测算法,结合设备机理模型动态修正偏差值。通过滑动窗口统计分析与频谱特征提取,自动识别周期性干扰并滤除非稳态噪声。清洗后的数据集在风电功率预测场景中,将模型训练误差降低至4.2%,较传统方法提升31%的精度。同时建立数据质量评分卡,从完整性、一致性、时效性三个维度量化评估,为工业数字孪生提供高可信度数据基座。通过标注眼底影像的微血管变化,明曦数智支持了慢性病筛查的AI辅助诊断。天桥区高质量数据集前景
明曦数智对网络公开数据执行版权筛查,确保训练数据来源合法,规避法律风险。山东高质量数据集多少钱
在构建关于罕见病的高质量数据集时,明曦数智遇到的难题是样本极度稀缺。有的病症全网可能都找不到几百张病例图。针对这种情况,团队不会盲目地去网上搜罗不可靠的信息,而是选择与几家专科医院合作,对历史归档数据进行结构化整理。由于数据量小,团队投入了双倍的人力进行精细化标注,甚至把CT影像的切片层厚、窗宽窗位等参数都详细记录下来。这种“少而精”的策略,确保了每一条数据都能经得起医学验证,虽然数据集规模不大,但在特定的辅助诊断场景中,其价值远高于那些泛泛而谈的大杂烩数据。山东高质量数据集多少钱
北京明曦数智科技有限公司在同行业领域中,一直处在一个不断锐意进取,不断制造创新的市场高度,多年以来致力于发展富有创新价值理念的产品标准,在北京市等地区的商务服务中始终保持良好的商业口碑,成绩让我们喜悦,但不会让我们止步,残酷的市场磨炼了我们坚强不屈的意志,和谐温馨的工作环境,富有营养的公司土壤滋养着我们不断开拓创新,勇于进取的无限潜力,北京明曦数智科技供应携手大家一起走向共同辉煌的未来,回首过去,我们不会因为取得了一点点成绩而沾沾自喜,相反的是面对竞争越来越激烈的市场氛围,我们更要明确自己的不足,做好迎接新挑战的准备,要不畏困难,激流勇进,以一个更崭新的精神面貌迎接大家,共同走向辉煌回来!