- 品牌
- 深信服
- 型号
- aServer-W-2305
超融合系统组成:1.缓存盘:缓存盘是混合阵列中的“加速层”,雪莱选用单盘容量一千九百二十GB的NVMe固态盘,每节点两块,同样做镜像。缓存盘里只放两份数据:一份是热数据,一份是写缓冲。缓存盘失效会触发“降级模式”,整体性能掉一半,但虚拟机依旧能跑。雪莱要求缓存盘必须在四小时之内换新,否则视为紧急故障。2.容量盘:容量盘就是存放冷数据的机械盘,雪莱目前使用七千二百转近线SAS盘,单盘容量八TB,每节点十二块。容量盘不做硬件Raid,而是把每块盘直接交给超融合软件,由软件把数据切片后分散到所有节点的所有硬盘。任何一块盘损坏,系统会在后台自动把缺失的切片补到剩余硬盘,恢复时间取决于数据量,一般控制在八小时以内。超融合系统支持故障自动检测与恢复,减少企业业务中断时间。河南数据超融合系统哪个好

为了保障计算任务的顺畅执行,上海雪莱信息科技在底层做足了优化功课。针对不同的业务类型——无论是数据库查询这类计算密集型操作,还是文件传输这种IO吞吐要求较高的场景,系统会自动识别并匹配较佳的资源分配策略。例如,对于频繁进行大数据运算的应用,会优先将其调度至剩余计算资源充足的节点;而对于实时性要求极高的交易系统,则会预留专门使用的计算通道,避免因资源共享导致的延迟波动。这种精细化的资源管理能力,本质上是对计算资源的“精打细算”,既避免了过度配置造成的浪费,又防止了资源不足引发的性能瓶颈。淮安超融合系统服务商上海雪莱信息科技有限公司的超融合系统针对海量小文件存储优化,提升存储效率。

选型实施的五个黄金准则:1.性能密度平衡:雪莱工程师建议以当前业务量的1.8倍作为基准,例如日均2000笔交易的系统应选择能承载3600笔的配置。2.扩展性验证:真实案例显示,3节点起步的集群扩展至8节点时,网络延迟需仍控制在初始值的115%以内。3.灾备实现方式:上海雪莱在华东某物流中心部署的双活架构,利用压缩去重技术将同步流量减少62%,使跨机房延迟稳定在2毫秒。4.运维能见度:其管理系统提供的200+监控指标,曾帮助某客户提前约37小时预测到磁盘故障。5.能耗效率:实测数据表明,传统架构每万元IT投资年耗电约4800度,而雪莱超融合方案可将此数值降至2100度左右。
可扩展性:横向扩展与集群弹性的平衡艺术。业务增长的不确定性要求超融合系统具备“按需扩展”能力。上海雪莱在为某在线教育平台设计架构时,采用“基础集群+弹性节点”的部署模式:初始部署4节点超融合集群支撑千人级并发课程,当用户量突破阈值时,通过在线添加2个计算节点与1个存储节点,实现计算资源与存储容量的单独扩展。集群规模是衡量扩展性的重要指标。上海雪莱参与的某地方云项目,通过部署32节点超融合集群支撑2000台虚拟机运行,创下国内同规模集群纪录。该集群采用分布式哈希表(DHT)实现元数据均匀分布,避免了单节点过载,且支持不停机扩容至64节点,满足系统未来5年的增长需求。企业采用超融合系统能够快速实现IT资源的弹性扩展与按需分配。
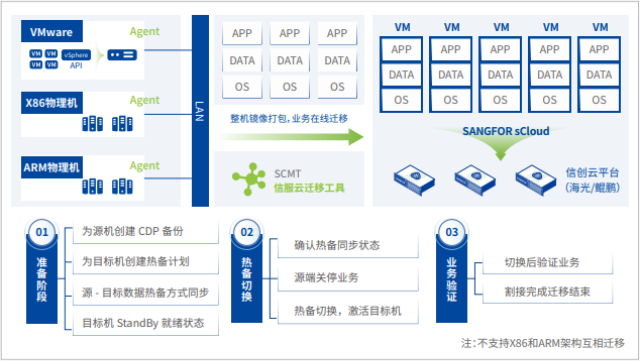
无法比拟的弹性与可扩展性,支撑业务平滑生长。市场的瞬息万变要求企业的IT系统必须具备快速响应业务变化的能力。传统架构在扩容时常常面临“不均等扩容”的困境:计算资源不足时,扩容服务器可能导致存储性能成为瓶颈;存储空间不足时,扩容存储阵列又可能浪费了剩余的计算能力。这种不匹配的扩容不*效率低下,更造成了资源的浪费。超融合架构以其独特的“Scale-Out”(横向扩展)模式完美地解决了这一问题。上海雪莱信息科技有限公司向客户阐释道,超融合集群的扩展就像用相同的积木搭建建筑,需要增加资源时,只需向现有集群中增加一个标准的节点即可。这个新节点会将其包含的计算能力和存储容量无缝地融入整个资源池中,系统会自动实现负载均衡,整个过程对上层业务应用完全透明,无需停机。超融合系统利用通用服务器硬件,降低企业 IT 基础设施初期采购成本。河南数据超融合系统哪个好
上海雪莱信息科技有限公司的超融合系统具备在线扩容能力,满足企业业务增长需求。河南数据超融合系统哪个好
在数字化转型加速推进的当下,企业对IT基础设施的灵活性、可靠性和运维效率提出了越来越高的要求。传统IT架构中计算、存储、网络资源相互割裂的问题日益凸显,而超融合系统的出现,为解决这一难题提供了切实可行的方案。作为深耕IT基础设施领域的专业企业,上海雪莱信息科技有限公司凭借对超融合技术的深刻理解与实践应用,为众多企业打造了高效稳定的IT基础架构,让超融合系统的价值得到充分彰显。无论是中小型企业的基础IT搭建,还是大型企业的复杂业务支撑,其打造的超融合系统都能通过资源的精确整合,实现基础设施与业务需求的高度匹配。河南数据超融合系统哪个好
上海雪莱信息科技有限公司为一家互联网金融平台构建的异地容灾方案,便是典型案例。该平台对业务连续性要求极高,监管机构也明确要求必须具备同城或异地容灾能力。上海雪莱利用超融合系统内置的异步复制技术,在主数据中心和灾备中心分别部署了两套超融合集群。主数据中心的生产数据会被持续不断地、增量式地复制到灾备中心。这套机制对上层应用完全透明,无需应用程序做特殊修改。一旦主数据中心因不可抗力发生故障,可以在灾备中心快速启动备份虚拟机,实现业务的接续。整个复制和切换过程都可以通过统一管理平台进行可视化的操作和演练,较大程度上提升了容灾流程的可控性和成功率。上海雪莱信息科技有限公司的技术团队具备丰富的超融合系统规...
- 宿迁深信服超融合系统服务商 2026-06-26
- 湖北深信服超融合系统 2026-06-25
- 超融合系统定制方案 2026-06-25
- 陕西数据超融合系统优势 2026-06-25
- 福建深信服超融合系统厂商 2026-06-24
- 安徽数据超融合系统报价 2026-06-23
- 江苏新一代超融合系统解决方案供应商 2026-06-21
- 贵州数据超融合系统方案 2026-06-20
- 深圳国内超融合系统基础架构 2026-06-18
- 湖北国内超融合系统方案 2026-06-17




- 湖州超融合系统管理平台 2026-06-14
- 甘肃超融合系统厂家 2026-06-13
- 深圳深信服超融合系统哪家好 2026-06-10
- 黑龙江数据超融合系统报价 2026-06-10
- 甘肃数据超融合系统哪家好 2026-06-09
- 安徽深信服超融合系统厂商排名 2026-06-06





- 上海并行分布式存储解决方案 06-26
- 湖北深信服超融合系统 06-25
- 超融合系统定制方案 06-25
- 陕西数据超融合系统优势 06-25
- 北京国产桌面虚拟化工作方式 06-24
- 福建深信服超融合系统厂商 06-24
- 图文分布式存储厂商排名 06-24
- 安徽图文分布式存储厂家 06-23
- 安徽数据超融合系统报价 06-23
- 天津国产桌面虚拟化应用场景 06-23