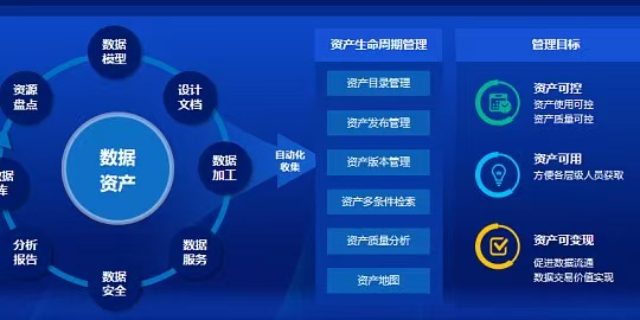
面向工业物联网场景,明曦数智数据集内置流式清洗管道,支持每秒百万级数据点的实时降噪与修复。针对传感器漂移、网络抖动等典型问题,研发基于物理约束的异常检测算法,结合设备机理模型动态修正偏差值。通过滑动窗口统计分析与频谱特征提取,自动识别周期性干扰并滤除非稳态噪声。清洗后的数据集在风电功率预测场景中,将模型训练误差降低至4.2%,较传统方法提升31%的精度。同时建立数据质量评分卡,从完整性、一致性、时效性三个维度量化评估,为工业数字孪生提供高可信度数据基座。明曦数智构建了多语种平行语料库,严格对齐句对,服务于机器翻译引擎训练。太原一站式高质量数据集服务热线

明曦数智在文本数据集构建中,重视语料的领域适配与均衡性。通过关键词检索与分层抽样,按比例采集不同子领域的语料,避免数据分布倾斜。针对专业术语密集的片段,引入领域专业人员参与标注校验,减少歧义,使数据集能更贴合特定行业的模型训练需求。
对于图像类高质量数据集,明曦数智建立了分辨率筛选与质量评分机制。利用算法自动过滤过低分辨率、过曝或模糊的图片,再辅以人工抽检。标注层面除目标检测框外,可根据需要增加属性标签,如光照条件、遮挡程度等,丰富数据的特征维度,提升训练样本的实用性。 太原高质量数据集供应商家通过采集手语动作数据,明曦数智建立了包含非手控特征的聋哑人交流数据集。
明曦数智在标注遥感影像数据集时,对于难以界定的地物采取了“存疑即弃”的原则。遥感图像由于拍摄角度和分辨率的限制,很多物体的边界非常模糊。例如,一片荒草地和一片待建的工地,在卫星图上可能看起来一模一样。如果强行标注,会给模型引入难以察觉的系统误差。因此,团队设立了“不确定”标签,并要求标注员在遇到此类情况时,宁愿不标也不要标错。这种看似“浪费”数据的做法,实际上是在保护模型的纯度。在后续的质检环节,这些“不确定”区域会被汇总,供算法工程师分析数据分布的盲区。
针对智慧交通流量预测数据集,明曦数智剔除了特殊事件日的异常数据。例如封控期间的流量数据,或者大型演唱会散场时的瞬间高峰数据,这些都属于不可复制的异常值。如果将这些数据混入训练集,模型会误以为这种极端情况也是常态,导致日常预测失灵。团队通过比对日历和历史事件库,将这些特殊日期的数据单独剥离出来,作为测试集或干脆剔除。这种“去噪”过程虽然减少了训练样本的总量,但净化了数据的分布,让模型学到的规律更加稳健和具有普适性。明曦数智在能源数据集中校准了采集设备的时差,确保多源数据的时间同步性。

明曦数智高质量数据集构建了覆盖文本、图像、时序信号、三维点云的全模态融合架构。通过自适应对齐技术,解决异构数据源的语义映射难题,实现跨模态实体统一表征。在数据治理层,引入动态血缘追踪机制,记录从采集、清洗到特征工程的全链路变更,确保每一条数据可回溯、可审计。针对长尾分布问题,采用基于信息熵的智能采样策略,提升小样本场景下的模型泛化能力。目前已支撑智能制造、智慧城市等领域的复杂决策需求,数据融合准确率达96.8%,降低多源数据协同应用的集成成本。明曦数智在自动驾驶数据中标注了复杂路口的博弈行为,提升决策规划能力。房山区高质量数据集
针对代码数据集,明曦数智标注了错误类型与修复逻辑,提升AI辅助编程能力。太原一站式高质量数据集服务热线
明曦数智在交付高质量数据集时,会随包附带一份详尽的《数据体检报告》。这份报告不会只报喜不报忧,而是客观地列出数据集的各项指标:总样本量、各标签分布比例、缺失值占比、标注一致率以及已知的局限性。例如,报告中会明确指出“本数据集中戴眼镜的亚洲人脸样本较少,模型在该场景下表现可能欠佳”。这种坦诚的沟通方式,帮助客户建立了合理的预期,避免了因盲目信任数据而导致的模型偏见问题。实事求是地展示数据的优缺点,是建立长期信任的基础。太原一站式高质量数据集服务热线
北京明曦数智科技有限公司是一家有着雄厚实力背景、信誉可靠、励精图治、展望未来、有梦想有目标,有组织有体系的公司,坚持于带领员工在未来的道路上大放光明,携手共画蓝图,在北京市等地区的商务服务行业中积累了大批忠诚的客户粉丝源,也收获了良好的用户口碑,为公司的发展奠定的良好的行业基础,也希望未来公司能成为*****,努力为行业领域的发展奉献出自己的一份力量,我们相信精益求精的工作态度和不断的完善创新理念以及自强不息,斗志昂扬的的企业精神将**北京明曦数智科技供应和您一起携手步入辉煌,共创佳绩,一直以来,公司贯彻执行科学管理、创新发展、诚实守信的方针,员工精诚努力,协同奋取,以品质、服务来赢得市场,我们一直在路上!