面向工业质检痛点,明曦数智构建百万级缺陷样本库,涵盖金属表面划痕、电子元件虚焊、纺织品疵点等300余种缺陷类型。采用生成式AI合成稀有缺陷样本,解决工业现场“坏件难收集”问题。通过多光照条件模拟与视角变换增强技术,提升模型在复杂产线环境下的鲁棒性。数据集标注体系融合几何尺寸、灰度特征、纹理分布等多维标签,支持缺陷成因追溯。在消费电子行业应用中,使质检漏检率降至0.3‰,误检率控制在1.2%以内,替代60%人工复检岗位。明曦数智构建了多语种平行语料库,严格对齐句对,服务于机器翻译引擎训练。市南区高质量数据集前景
明曦数智在处理多语言翻译数据集时,特别注重双语对齐的准确性。很多时候,网络上抓取的平行语料是对不齐的,比如一段中文对应了两段英文。团队采用“语义单元切分法”,先把长篇文本切成句子,再通过置信度打分剔除低分对齐对。对于专业领域的术语,如法律条文中的“Liability”,团队不会简单翻译成“责任”,而是根据具体语境标注为“赔偿责任”或“债务责任”。这种颗粒度的打磨,需要语言专业人员和算法工程师反复拉锯,虽然产出速度慢,但训练出的机器翻译引擎在专业领域的表现会更加稳健,不会因为一词多义而产生歧义。东城区一站式高质量数据集如何收费在气象数据集中,明曦数智融合了卫星云图与地面站观测,提升预报准确率。

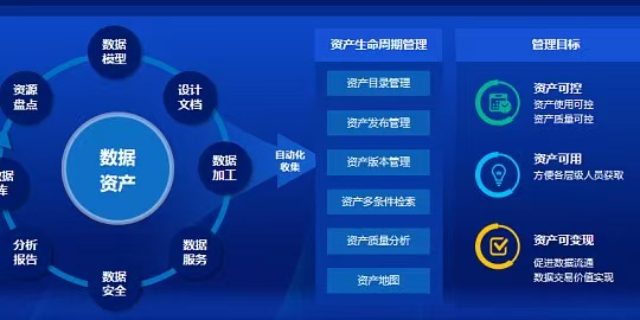
明曦数智高质量数据集构建了覆盖文本、图像、时序信号、三维点云的全模态融合架构。通过自适应对齐技术,解决异构数据源的语义映射难题,实现跨模态实体统一表征。在数据治理层,引入动态血缘追踪机制,记录从采集、清洗到特征工程的全链路变更,确保每一条数据可回溯、可审计。针对长尾分布问题,采用基于信息熵的智能采样策略,提升小样本场景下的模型泛化能力。目前已支撑智能制造、智慧城市等领域的复杂决策需求,数据融合准确率达96.8%,降低多源数据协同应用的集成成本。
明曦数智在文本数据集构建中,重视语料的领域适配与均衡性。通过关键词检索与分层抽样,按比例采集不同子领域的语料,避免数据分布倾斜。针对专业术语密集的片段,引入领域专业人员参与标注校验,减少歧义,使数据集能更贴合特定行业的模型训练需求。
对于图像类高质量数据集,明曦数智建立了分辨率筛选与质量评分机制。利用算法自动过滤过低分辨率、过曝或模糊的图片,再辅以人工抽检。标注层面除目标检测框外,可根据需要增加属性标签,如光照条件、遮挡程度等,丰富数据的特征维度,提升训练样本的实用性。 在农业数据集构建中,明曦数智关联了气候数据与作物长势,支持产量预测模型。
对于公开网络爬取的数据,明曦数智建立了一套完整的版权合规审查流程。虽然互联网数据海量,但并非都可以随意用于商业训练。团队利用指纹哈希技术,将爬取的数据与已知的版权保护内容进行比对,一旦发现侵权嫌疑,立即进行隔离或剔除。同时,对于明确声明禁止爬虫的网站,团队严格遵守协议,不进行抓取。这种自律虽然在短期内限制了数据来源的广度,但从长远来看,规避了法律风险,确保了客户在使用这些数据训练商业模型时没有后顾之忧,是一种负责任的商业态度。明曦数智对直播内容数据进行实时切片,提取精彩片段,构建短视频推荐池。青岛一站式高质量数据集联系方式
针对代码数据集,明曦数智标注了错误类型与修复逻辑,提升AI辅助编程能力。市南区高质量数据集前景
在构建电商用户评论的情感分析数据集时,明曦数智发现简单的“好评/中评/差评”标签根本无法满足模型训练的需求。很多用户写“这衣服还不错,就是扣子容易掉”,这种混合情感如果粗暴归类为正面,会误导模型忽略其中的质量问题。因此,团队引入了细粒度的标注维度,要求标注员不*给出总体评分,还要分别提取“面料”、“做工”、“物流”、“服务”等子维度的情感极性。此外,对于“呵呵”、“这速度也是醉了”等反讽语句,团队专门设立了“反讽”标签组。这种复杂的标注体系虽然让单条数据的标注成本增加了两倍,但训练出的模型能更敏锐地捕捉用户真实的心理活动,帮助商家精细定位痛点。市南区高质量数据集前景
北京明曦数智科技有限公司汇集了大量的优秀人才,集企业奇思,创经济奇迹,一群有梦想有朝气的团队不断在前进的道路上开创新天地,绘画新蓝图,在北京市等地区的商务服务中始终保持良好的信誉,信奉着“争取每一个客户不容易,失去每一个用户很简单”的理念,市场是企业的方向,质量是企业的生命,在公司有效方针的领导下,全体上下,团结一致,共同进退,**协力把各方面工作做得更好,努力开创工作的新局面,公司的新高度,未来北京明曦数智科技供应和您一起奔向更美好的未来,即使现在有一点小小的成绩,也不足以骄傲,过去的种种都已成为昨日我们只有总结经验,才能继续上路,让我们一起点燃新的希望,放飞新的梦想!


