明曦数智在文本数据集构建中,重视语料的领域适配与均衡性。通过关键词检索与分层抽样,按比例采集不同子领域的语料,避免数据分布倾斜。针对专业术语密集的片段,引入领域专业人员参与标注校验,减少歧义,使数据集能更贴合特定行业的模型训练需求。
对于图像类高质量数据集,明曦数智建立了分辨率筛选与质量评分机制。利用算法自动过滤过低分辨率、过曝或模糊的图片,再辅以人工抽检。标注层面除目标检测框外,可根据需要增加属性标签,如光照条件、遮挡程度等,丰富数据的特征维度,提升训练样本的实用性。 针对环境监测数据,明曦数智剔除了传感器漂移产生的异常值,保证数据真实。天桥区一站式高质量数据集多少钱

数据集的类别平衡是明曦数智在项目中反复强调的技术要点。曾经有一个人脸识别项目,由于训练数据中女性戴帽子的样本极少,导致算法在识别戴帽女士时准确率骤降。发现问题后,团队并没有选择重新采集几十万张新图片,而是采用了“定向增补”策略。他们利用现有的少量戴帽样本,结合GAN(生成对抗网络)技术生成多样化的变体,同时辅以少量的真实补采。这种“虚实结合”的方法,在不打破原有数据分布的前提下,有效地解决了长尾问题。这体现了明曦数智在处理数据不平衡时的灵活性,既不过度依赖昂贵的人工采集,也不盲目相信合成数据。清徐高质量数据集联系方式通过持续的数据清洗与回流,明曦数智确保了数据集在业务演进中的长期有效性。

做新闻摘要数据集时,明曦数智发现网络上抓取的大量摘要其实是“标题党”或简单的复制粘贴。为了训练出真正具备抽象概括能力的模型,团队投入了大量人力进行“摘要重写”。标注员需要阅读长文,然后用自己的话写出精炼的总结,而不能直接抄袭原文的句子。这种生成式摘要的数据集构建难度极大,因为每个人的写作风格不同,容易产生不一致。为此,团队制定了严格的摘要长度限制、禁止引用原文长句等规则,并进行了多轮校对。这种“笨功夫”换来的是数据集的高质量,让模型学会了真正的归纳总结,而不只是寻找关键词。
北京明曦数智科技高质量数据集集成联邦学习与多方安全计算技术,构建“数据可用不可见”的合规流通范式。在数据标注阶段采用差分隐私保护机制,通过拉普拉斯噪声注入确保个体信息不可逆向推导。针对跨境数据流动需求,设计细粒度权限控制系统。经中国信通院隐私计算测评,其数据泄露风险低于0.01%,满足GDPR与《数据安全法》双重要求。已在医疗科研领域实现多家医院数据协同建模,患者隐私零泄露前提下,疾病预测模型AUC提升至0.912。针对代码数据集,明曦数智标注了错误类型与修复逻辑,提升AI辅助编程能力。
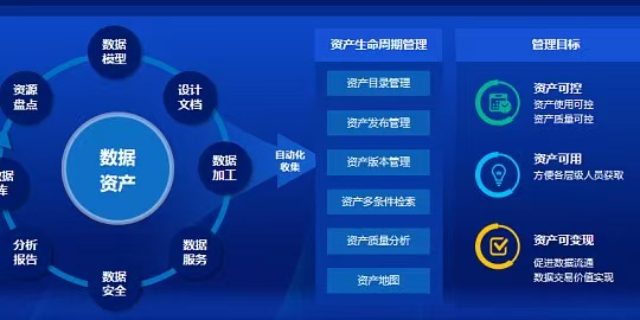
明曦数智在执行数据质检时,引入了统计学中的“卡方检验”来检测标注的一致性。人工标注难免会有主观差异,特别是对于那种模棱两可的样本。团队会随机抽取10%的数据,交给不同的标注员进行盲测。如果两名标注员对同一批数据的标签分布差异超过了预设的置信区间,系统就会判定这批数据存在系统性偏差。此时,项目经理会介入,重新审视标注规范是否存在歧义,并组织全体标注员进行再次培训。这种基于统计学的质控手段,虽然增加了管理成本,但有效地杜绝了“萝卜快了不洗泥”的现象,保证了数据集的质量下限。针对安防监控数据,明曦数智去除了静止背景,聚焦人车物等关键目标的轨迹。太原一站式高质量数据集怎么样
通过采集生产线振动数据,明曦数智建立了机械设备健康状态的评估基准数据集。天桥区一站式高质量数据集多少钱
明曦数智高质量数据集构建了覆盖文本、图像、时序信号、三维点云的全模态融合架构。通过自适应对齐技术,解决异构数据源的语义映射难题,实现跨模态实体统一表征。在数据治理层,引入动态血缘追踪机制,记录从采集、清洗到特征工程的全链路变更,确保每一条数据可回溯、可审计。针对长尾分布问题,采用基于信息熵的智能采样策略,提升小样本场景下的模型泛化能力。目前已支撑智能制造、智慧城市等领域的复杂决策需求,数据融合准确率达96.8%,降低多源数据协同应用的集成成本。天桥区一站式高质量数据集多少钱
北京明曦数智科技有限公司是一家有着雄厚实力背景、信誉可靠、励精图治、展望未来、有梦想有目标,有组织有体系的公司,坚持于带领员工在未来的道路上大放光明,携手共画蓝图,在北京市等地区的商务服务行业中积累了大批忠诚的客户粉丝源,也收获了良好的用户口碑,为公司的发展奠定的良好的行业基础,也希望未来公司能成为*****,努力为行业领域的发展奉献出自己的一份力量,我们相信精益求精的工作态度和不断的完善创新理念以及自强不息,斗志昂扬的的企业精神将**北京明曦数智科技供应和您一起携手步入辉煌,共创佳绩,一直以来,公司贯彻执行科学管理、创新发展、诚实守信的方针,员工精诚努力,协同奋取,以品质、服务来赢得市场,我们一直在路上!


