- 品牌
- 智会云
- 型号
- ICCT-200YY
- 产地
- 广州
- 可售卖地
- 全国
- 是否定制
- 是
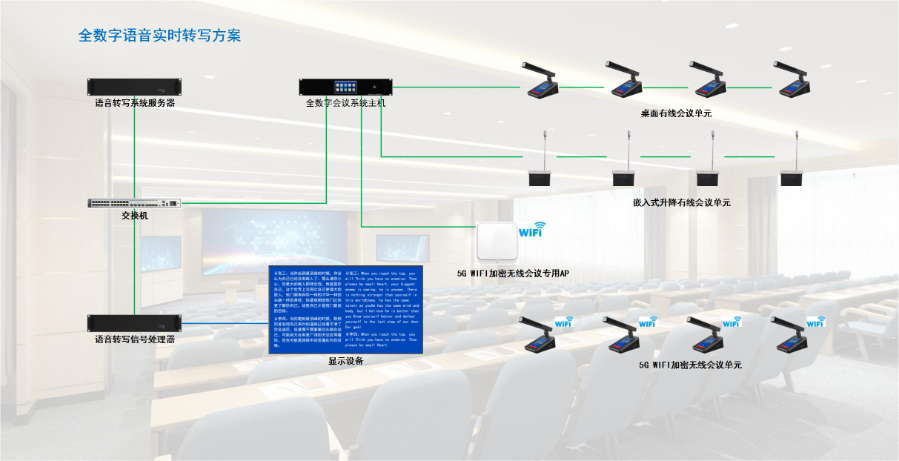
语音转写产品是通过人工智能技术,将人类语音信号实时或离线转化为文字的工具,重心价值在于打破 “听” 与 “读” 的信息传递壁垒,提升信息处理效率。其工作流程包含语音采集、信号预处理、特征提取、模型识别、文字输出五大环节,主流技术基于深度学习中的语音识别模型(如 CNN、RNN、Transformer 架构),可支持多语种、多场景下的精细转写。相比传统人工记录,语音转写产品能实现分钟级处理,准确率普遍达 95% 以上,且可通过个性化训练优化专业领域术语识别。无论是会议记录、课程整理还是采访归档,它都能减少人工重复劳动,让使用者更聚焦于内容本身,而非信息记录环节。农业场景中,语音转写离线记录农情,关联地理位置生成可视化种植档案。南京多语种识别语音转写软件系统

不错语音转写产品注重用户社群运营,构建完善的用户服务生态。在社群运营上,建立官方用户交流群(如按行业分类的职场群、教育群、法律群),定期组织线上分享活动,邀请熟练用户讲解使用技巧(如 “如何提升专业领域转写准确率”“高效整理会议记录方法”),产品团队也会在群内收集需求、解答疑问,增强用户粘性;在服务延伸上,推出 “专属顾问” 服务,付费会员可享受一对一专属顾问指导,针对个性化需求(如企业系统集成、特殊场景适配)提供定制化解决方案,同时提供定期使用报告,分析用户转写习惯,给出效率提升建议;此外,社群内还会开展用户共创活动,邀请用户参与新产品功能测试,收集反馈并优化,让用户参与产品成长,提升用户认同感。长沙多角色语音转写作用语音转写的音频修复模块可优化老旧音频质量,提升磁带转录文件的转写效果。

语音转写产品具备全场景适配优势,能灵活满足不同行业、不同人群的多样化使用需求,打破场景局限。在职场领域,适配会议记录、客户访谈、项目汇报等场景,支持多 speaker 分离、重点标注功能;在教育领域,适配课堂教学、学术讲座、学生笔记场景,提供知识点提取、双语对照功能;在生活领域,适配家庭录音整理、自媒体口播脚本创作、老人语音记事场景,支持轻量化操作与离线使用;在专业领域,还能深度适配医疗病历记录、法律庭审记录、物流调度沟通等垂直场景,提供符合行业规范的定制化功能。无论是室内安静环境还是户外嘈杂环境,无论是短时长语音还是数小时长音频,产品都能稳定发挥作用,真正实现 “全场景可用”。
语音转写产品升级 AI 辅助编辑功能,从基础纠错向深度内容优化延伸。在内容提炼上,支持 “智能摘要生成”,转写完成后,系统基于语义分析自动提取重心观点、关键数据、待办事项,生成 100-300 字的精简摘要,适配快速浏览需求;在风格优化上,提供 “场景化风格调整”,用户可选择 “商务正式”“口语通俗”“学术严谨” 等风格,AI 会自动调整语句结构与词汇,例如将口语化的 “大概下周弄完” 优化为商务表述 “预计下周完成”;在格式排版上,支持 “智能结构化整理”,针对会议记录自动按 “参会人 - 议题 - 讨论结果 - 行动项” 分区,针对课程笔记自动按 “章节 - 知识点 - 案例” 分层,减少手动排版时间,让转写文档更具条理性。视障用户使用语音转写时,屏幕阅读器同步播报内容,辅助完成操作。
为满足残障用户需求,语音转写产品推出无障碍服务适配功能。针对视障用户,产品支持与屏幕阅读器深度兼容,转写过程中的操作提示、文字内容可通过语音播报同步输出,方便视障用户完成转写启停、文档保存等操作;针对听障用户,除实时语音转文字外,还支持 “文字转语音” 反向功能,听障用户输入文字后,系统可转化为清晰语音与他人沟通,同时转写内容可生成超大字体版本,适配听障用户阅读习惯;针对肢体残障用户,产品支持语音控制功能,用户通过 “开启转写”“导出文档” 等语音指令即可操作,无需手动点击,同时适配外接辅助设备(如定制键盘、摇杆),降低操作难度。这些无障碍适配让残障用户能便捷使用语音转写服务,享受科技带来的便利。小语种语音转写已覆盖越南语、泰语等,满足跨境贸易多语言记录需求。北京自动翻译语音转写云平台
车载场景中,语音转写记录驾驶时的灵感,同步至手机端供后续编辑。南京多语种识别语音转写软件系统
针对方言与不同口音的识别难题,语音转写产品研发了专项适配技术。技术层面,通过构建多语种、多方言语音数据库,涵盖粤语、四川话、东北话等主流方言及各地方口音普通话,采用迁移学习算法,让模型在通用语音识别基础上,快速适配特定方言与口音特征;同时,引入口音自适应训练功能,用户可上传少量带口音的语音样本,模型通过学习调整识别参数,提升个人语音转写准确率。部分产品还推出方言转写专项版本,针对特定地区用户需求,优化方言词汇、语法识别逻辑,例如识别粤语中的 “唔该”“系啊” 等常用词汇,解决方言沟通场景下的转写痛点,拓宽产品适用人群范围。南京多语种识别语音转写软件系统

语音转写软件的精细性使其在众多领域备受青睐,这得益于先进的技术支撑.其精细识别依赖复杂的声学和语言模型分析.声学模型能细致分析和建模语音的声学特征,无论语音的音色、语调、音量如何变化,都能精细捕捉细节.语言模型基于大规模语料库训练,能理解不同语境下的语义信息,准确将语音转化为文字.在实际应用中,对于各种口音,如不同地区方言或特定文化背景下的口音,软件都能较好识别关键信息.面对连读、弱读等复杂语音现象,也能通过智能算法处理,还原语义.比如在快速对话场景下,软件能通过音素分析准确识别连读内容.其高准确的识别结果减少了人工校对工作量,让用户能更专注于信息处理和分析.语音转写的权限分级管理让企业按岗位...
- 北京文字识别语音转写软件 2026-04-30
- 长沙AI智能语音转写有什么功能 2026-04-30
- 北京多角色语音转写价格 2026-04-30
- 上海智能语音转写软件 2026-03-14
- 长沙音频转文字语音转写云平台 2026-03-14
- 长沙AI智能语音转写软件系统 2026-03-14
- 南京会议纪要语音转写软件 2026-03-14
- 长沙会议纪要语音转写软件 2026-03-13
- 广州角色分离语音转写同时翻译 2026-03-13
- 无纸化语音转写 2026-03-13


- 多角色语音转写价格 2026-03-12
- 南京实时语音转写报价 2026-03-11
- 文字识别语音转写云平台 2026-03-11
- 长沙会议纪要语音转写作用 2026-03-11
- 上海AI智能语音转写售后 2026-03-11
- 上海语音转写故障排除 2026-03-10

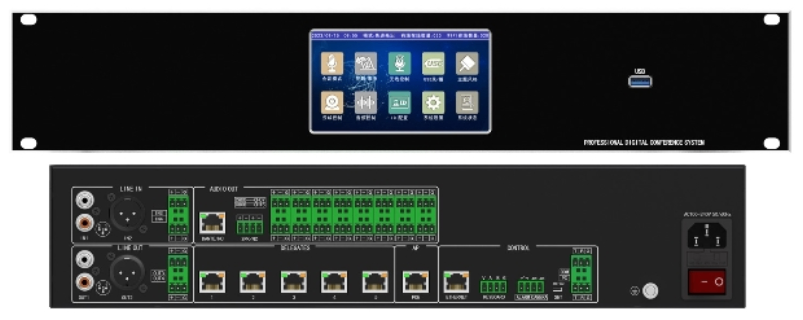


- 北京鹅颈数字会议软件系统 04-10
- 南京方型话筒数字会议云平台 04-10
- 广州多媒体数字会议系统 04-10
- 智慧办公会议预约作用 04-09
- 上海多功能数字会议故障排除 04-08
- 上海数字会议哪家好 04-08
- 国产智能无纸化会议售后维护 04-08
- 长沙国产智能无纸化会议报价 04-08
- 上海智能语音转写软件 03-14
- 长沙音频转文字语音转写云平台 03-14